Overview
What is Janus?
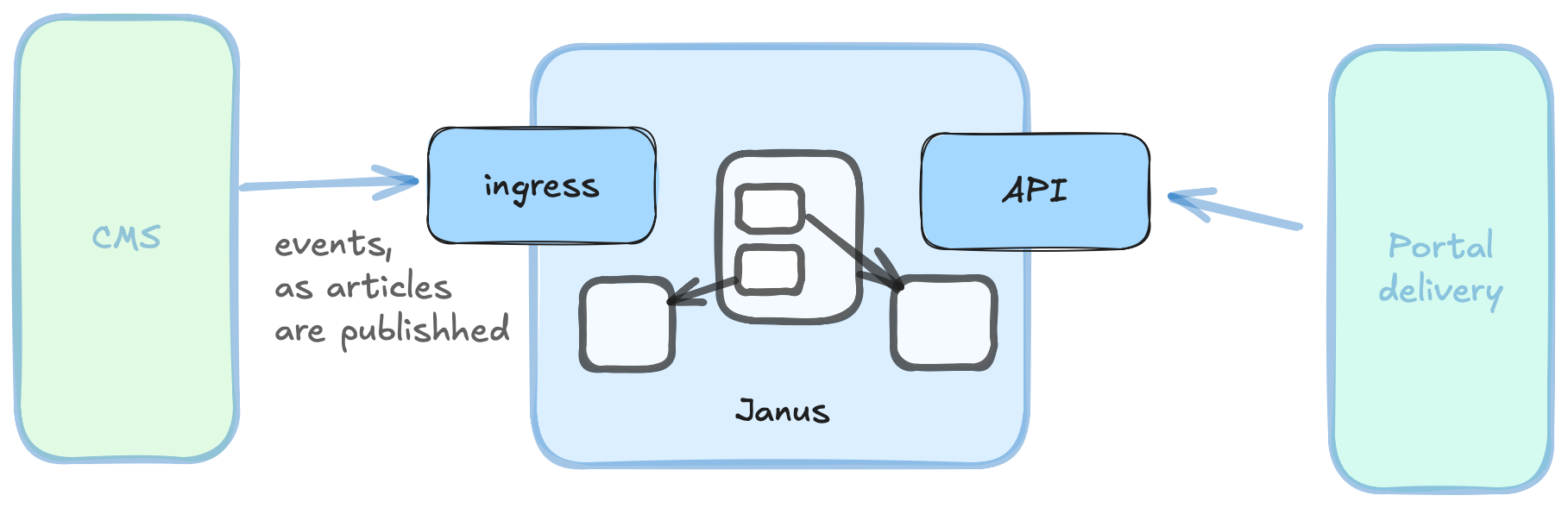
Janus is a system geared towards helping you deliver, efficient, highly performant, always up-to-date news portals.
Janus provides an instantaneously updated view of content, fulfilling all your frontend needs via an easy-to-use API. Whether that is on a web application, mobile web-view or native apps, this solution restructures the content, optimizing it for fast, single request access via the API, making sure all the data you need to render is present.
Janus has excellent performance characteristics which make a content CDN an optional choice in your architecture. Most entity lookup operations are essentially hash-table access operations.
Main Features
Incremental Processing
A Headless CMS is typically concerned with the following issues:
-
data consistency (as it is the source of truth)
-
content editing the system is geared towards being responsive for authoring use cases.
Because of this, the data in the CMS is kept in a normalized form, which is advantageous when editing and keeping data correct. This means references from one document to another are stored just as identifiers.
A portal delivery system has different priorities. It needs all the necessary data to render a single document as fast as possible.
For example, a front-page typically has (hundreds of) references towards articles. In the CMS they are stored just as IDs. When we are rendering the page though, need the title of the article, its teaser image, author, etc…
In other words we need to resolve these references to the required content.
Fulfilling this requirement directly from a normalized data store is not something that can be done effectively with a throughput with a satisfactory latency typically needed for building high-traffic web front-ends (a single document can easily refer to dozens if not hundreds of other documents). This is why current approaches rely heavily on caches — it takes seconds to assemble the content needed for a typical page.
To address this problem, Janus takes a different, event-driven approach. Instead of resolving the references at the time they are needed, it does that at the time they are published or updated
Furthermore, Janus keeps track of how the documents are linked between each-other so that it can effectively apply changes as they are published in the CMS everywhere needed.
Consistent Data Model
The general philosophy with respect to data modeling in Janus is "recognize to leverage".
CMS data is typically a semi-structured collection of documents, which are themselves loosely structured trees. Data managed by one media house is typically similar to another in their respective CMS, but it is never quite the same.
To be well integrated in the today’s WWW, a site needs to provide machine-readable metadata in a variety of forms that help search engines, social networks, messaging systems, and other tools with presentation and promotion of the content.
In other words, it makes sense to represent certain data from most features available on a page in a standardized form. One can leverage Janus with the following out-of-the-box features:
Content structure on a live site changes frequently. Therefore, it is not worth the additional effort and opportunity cost of an extended time to market content, to fully translate the entire CMS data into a standard form that will be delivered to front ends.
Instead, Janus takes the approach of overlaying standardized metadata on top of the CMS content. Developers can use its pattern matching facilities to recognize data patterns and translate them to the standardized metadata that Janus understands. The standardized Janus metadata lives along with the content and is delivered via the REST API. The client libraries also rely on this metadata to provide a convenient portal developing experience.
For example, if one can recognize the article’s title, routing information and teaser, one unlocks the sitemaps feature. If one can recognize/pattern-mach/map the teaser metadata to the standard Janus representation, one unlocks the so-called SEO features (OpenGraph, Schema.org annotation, RSS feeds.
Ingress
TODO: Picture.
Janus supports having multiple ingresses feeding data from various sources.
An ingress is responsible for monitoring a data source for changes and feeding those changes into the system as soon as they happen.
Typically one main ingress is set up for the CMS, with additional ingresses for various supplementary sources such as:
-
recommendation systems
-
data sources for sport, weather, …
-
etc..
Janus' pattern matching and linking facilities allow for excellent combination of data coming from the various sources into a single easy to use presentation geared towards the web delivery.
| For example, a recommendation system feeds article ids for the "most read articles" list. This data is ingested into Janus, the ids resolved to teaser metadata and inserted in the appropriate pages. Once this is done, any change in any of the sources is correctly updated in the resulting document. |
Livingdocs Ingress
Janus supports Livingdocs out of the box.
REST API
The content from Janus is available via a simple self-describing REST API.
You can examine an instance of it here.
You can download the OpenAPI specs as well.
The central endpoint of the API is the
resolved
entity endpoint. By supplying it an origin identifier (site name) and
path, one gets the document behind it ready to serve.
The endpoint will use the Routing feature to resolve the document behind the path and then quickly return the up-to-date, ready-to-render document. No further requests are necessary for the web-portal to fulfill the request.
Routing
Janus supports bi-directional routing.
-
given an
originand apathit can very quickly return the document behind it, or a redirect instruction if such has been configured -
Given a document, very quickly produce a full URL for each origin on which that document is available.
In addition, there is a an API and a admin tool that allows for ad-hoc route definitions, e.g. setting up redirects directly to documents or to other URLs.
Dynamic Lists
| The name of the feature perhaps is worth considering. |
Dynamic Lists is the reactive querying feature of Janus allowing the media house to employ the desired level of automation in page building.
Unlike a classical query system (like ElasticSearch) where, one runs the query at the point when data is needed, Janus maintains the results of the submitted dynamic lists incrementally, as changes of the content arrive. This is much more resource efficient and more performant:
-
work is done incrementally only when changes happen, as opposed to running expensive queries on demand — queries that most of the time return the same result
-
results are always ready (and therefore fast) and up to date
| The reason for this is that a typical publishing system receives changes from the editors in the order of hundreds per day. At the same time the page views on the a single site is easily in the millions per day range. Even with caching, to keep the site fresh, the number of such queries hitting the system is in the millions per day range. In consequence, the response for each individual query will be the same most of the time. |
The lists participate in the overall content structure just like any other content, meaning, they can be included by other documents and will participate in the automatic change propagation across the board.
To use them, one submits a list (essentially a query) to Janus via:
-
the REST API for ad-hoc dynamic lists
-
the pattern matching mechanisms, to support automation use-cases that originate in the CMS (typically automatic teaser containers, etc.)
This features underpin quite a number of end-user facing solutions such as:
Automatic Pages
One submits a dynamic list to the system matching articles of the desired criteria. This automatically produces a document which is always up to date and reflects the results of that query as changes happen in the system.
This can be used to build automatic pages for:
-
authors (all articles by each author in the system)
-
topics (all articles for each topic in the system)
-
locales (cities, regions, etc..)
-
categories
Teaser Placement
Using the pattern matching mechanisms of Janus one can detect configuration stemming out of the CMS that expresses some intent on automatic teaser placement within a page or an article:
-
related articles (belonging to the same category, topic, …)
-
filling out an automatic teaser container on homepages, department pages, etc.
-
selecting the most important article to show at a certain position based on some criteria
Sitemaps
Janus provides out of the box sitemaps for each origin it supports. The base format, along with the Google News sitemaps extension are supported.
All sitemaps are always up to date and incrementally maintained.
The Janus REST API provides the correct formats and can be set up within minutes with a few simple redirects / routing rules.
RSS Feeds
Leveraging the standardized metadata around article teasers, we are able to provide an out of the box RSS rendering of every document via the REST API.
By requesting an the content type application/rss+xml for a
document, one obtains an automatic RSS rendition of it. This is done
by scanning the document for teasers, converting them into RSS
format.
Thus it is very easy to include RSS links in pages and route these requests directly to Janus.
User Preferences
Janus includes an out of the box, high performance user preferences module that allows your site to implement:
Bookmarks
Via the REST API one can manage bookmarks for each individual user across devices and browsers.